В последние 10 лет популярность искусственного интеллекта растет чрезвычайно быстро благодаря разработке новых версий нейронных сетей — распознавателей образов и больших языковых моделей. Достижения реальны и охватывают многие области бизнеса, повседневной жизни и человеческой деятельности. Автор является активным пользователем ChatGPT. Цель данной статьи — указать на недостатки, присущие этому инструменту, которые могут стать причиной значительного вреда для бизнеса и людей.
Краткая история ИИ
Историй искусственного интеллекта было написано несколько. Все они начинаются с сети искусственных нейронов Маккаллаха и Питта для имитации работы мозга (1943) и философской работы Тьюринга "Вычислительная техника и интеллект" (1950). Как они смотрели в будущее? Маккаллах и Питт были настроены очень оптимистично и обещали огромные дивиденды психиатрии, нейрофизиологии и компьютерной биологии. Например, "для психиатра важнее то, что в таких системах "Разум" больше не будет "призрачнее призрака". Вместо этого больная психика может быть понята без потери масштаба или строгости, в научных терминах нейрофизиологии" (McCullagh 1943).
Тьюринг подошел к проблеме фундаментально, определив основные понятия "машина" и "мышление". Стоит подчеркнуть, что никто из них не утверждал, что целью является создание интеллектуальной машины — машины, способной мыслить. Маккаллах и Питт хотели использовать сети искусственных нейронов для понимания работы человеческого мозга, а Тьюринг заявил, что речь идет об имитации мышления.
Следующим шагом стал перцептрон, предложенный Розенблаттом в 1957 году (Rosenblatt 1957). Это было аналоговое электрическое устройство, в котором была реализована идея обучения — концепция, доминирующая в области ИИ до сегодняшнего дня. Перцептрон предназначался для распознавания образов, и первыми объектами для распознавания были буквы и цифры. Эта тема присутствовала на протяжении всей истории ИИ. Обсуждение этой линии развития позволит нам в итоге понять суть самых современных продуктов нейронных сетей — больших лингвистических моделей.
Очень скоро после появления работы Розенблатта процедура обучения была обобщена и представлена как поиск поверхности в многомерном пространстве, разделяющей обучающие векторы, принадлежащие двум классам. С самого начала было ясно, что перцептрон не может обобщать буквы: получив для обучения конкретную "а", он не может распознать ту же "а", сдвинутую вниз. Тогда буквы были представлены в виде вектора признаков (например, количества отверстий, концов, пересечений траекторий и т.д.). Обучающие данные состояли из десятков примеров каждой буквы, использовалось несколько различных алгоритмов, но результаты (количество ошибок) были неприемлемо высоки. Причина была ясна: необычная форма, размер, расположение или наклон изображений букв и цифр. Решение проблемы было очевидным: увеличить разнообразие букв и цифр в обучающем наборе. Это было сделано путем увеличения количества обучающих примеров от разных писателей. В 70-х годах количество обучающих примеров достигло 200, но результаты все равно были не очень хорошими.
В 80-х перцептрон вернулся на сцену, когда был преобразован в многослойную нейросеть с прямой связью.. Однослойный перцептрон был способен обучать только линейно разделяемые паттерны. Скрытые слои проецируют входное пространство в пространство более высокой размерности, в котором можно линейно разделить два класса точек, неразделимых во входном пространстве. Для нахождения разделяющей гиперплоскости использовался метод градиентного спуска для минимизации функции потерь. Для распознавания это было равносильно получению водородной бомбы — любая проблема может быть решена. Но ученые, разработавшие бомбу, предупреждали об опасности оружия, а адепты нейронных сетей хранили молчание.
Разбор ошибок распознавания образов
В экспериментальных науках (да и в жизни тоже) важнейшим условием прогресса является анализ ошибок. Давайте займемся этим. Вот несколько примеров неправильно распознанных цифр, сделанных одной из удачных версий нейронных сетей (уровень ошибки 0,82%).
1. Причины ошибок на рисунке очевидны: первые пять изображений демонстрируют ошибки в различении "3" и "5". Обе цифры состоят из двух частей:
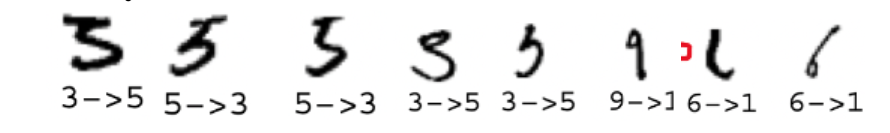
Горизонтальный штрих (или дуга) вверху и S-образная фигура под ним. S-образная фигура (часто пишется как одиночный штрих) соединяется с правым концом верхнего штриха в "3" и к левому концу в "5". "3" пишется без отрыва пера от бумаги. Человек видит, что второе и третье изображения на рисунке нарисованы с перерывом, и, следовательно, оба интерпретируются как "5", а первое — как "3". Суждение нейронной сети легко понять: вторая часть обеих цифр очень похожа и занимает большую часть площади цифры, а значит, на нее приходится большая часть значения сходства. Соответственно, решение будет приниматься только по сходству S-части. Пятая цифра не может быть распознана человеком как "3" или "5". Нейронная сеть приняла решение, найдя цифру с наиболее похожей S-частью. Таким образом, несмотря на то, что тысячи цифр "3" и "5" были распознаны правильно, распознаватель не пройдет тест Тьюринга — человек не может давать такие ответы. Подобное поведение нейронной сети можно наблюдать на следующих примерах. На рисунке все цифры имеют доминирующую часть — вертикальную линию. Нейронная сеть обнаружила, что наиболее похожими цифрами являются "1", игнорируя небольшие, но значимые части цифры.
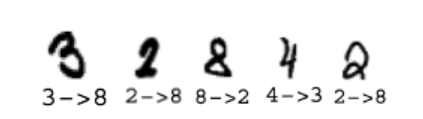
Легко понять, что если в наборе обучающих данных MNIST есть 6000 цифр для каждой из 10 цифр, то: 1) встречаются изображения "8", которые перекрывают первую, третью и пятую цифры в нашем примере более чем на 80%, и 2) бывает, что в обучающих данных нет изображений "8", которые совпадают с этими тремя изображениями более чем на 90%. Это еще раз показывает, что мера сходства (перекрытие) не подходит для данной задачи. Это говорит о том, что нейронная сеть не обобщает. Причину этого мы обсудим позже.
2. Увеличение данных
— это воспроизведение каждого изображения обучающих данных с помощью различных видов искажений (сдвиг, наклон, поворот и так называемые эластичные искажения) и добавление их в обучающий набор. Это было сделано потому, что нейронная сеть не может правильно распознать любую цифру из обучающего набора, если она сдвинута на два пикселя вправо, поскольку мерой сходства является степень перекрытия. Это означает, что обобщение равно нулю.3. Около 20 лет назад было обнаружено, что изображения, правильно классифицированные нейронной сетью после небольших невидимых глазу помех становятся неузнаваемыми для нейронной сети (adversarial images).

Следующий пример спорного образа является серьезным предупреждением:


В заключении отчета, выпущенного создателями GPT-4, перечислены задачи на будущее. Главная из них — борьба с такими манипуляциями нейронных сетей. В 2019 году Балдоминос, в статье посвящённый adversarial attacks (Baldominos 2019), начал “копаться” в процедуре градиентного спуска, вычисляющей функцию принятия решения, которая разделяет векторы, принадлежащие разным классам. Но задача состояла не в том, чтобы избавиться от ошибок, а в том, чтобы их найти. Они правильно рассудили, что две состязательные картинки, которые выглядят одинаково, но распознаются по-разному, должны в пространстве, где осуществляется градиентный спуск, 1) располагаться рядом, и 2) подделка должна иметь гораздо меньший балл, чем в той точке, в которой она была распознана правильно. Затем в программе поиска ошибок на основе состязательности авторы из начальной точки перемещают градиент немного вверх, чтобы добраться до области, где есть ошибка. Они находят двойников, но не всех. Иллюстрации к этим аргументам показывают, что они плохо понимают ситуацию: 1) точки трех классов лежат в отдельных компактных кучках, 2) двойник лежит далеко от своей кучки, то есть далеко от своего родителя. Правильная картина заключается в том, что разделительная функция, разделяющая точки разных классов в многомерном пространстве с помощью гиперплоскости, при отображении разделительной поверхности обратно в низкоразмерное входное пространство становится очень сложной и разбивается на множество разделенных областей, многие из которых имеют малый диаметр и содержат одну точку. Это позволяет точке, принадлежащей к другому классу, находиться недалеко от этой точки. Единственным решением проблемы является отказ от такого многомерного пространства, в котором любые два набора точек могут быть разделены на 100%.
Корни ошибок
Анализ ошибок нейронных сетей показывает, что они распознают только такие новые цифры, которые являются почти идеальными копиями одной из цифр обучающего набора — никакой генерализации и никакого интеллекта. Описанное выше поведение нейронных сетей невозможно для человека, поэтому нельзя утверждать, что нейронные сети — это модель работы мозга.
Какие ошибки были допущены при разработке нейронных сетей?
- Идея о том, что мозг состоит из нейронов, так же ошибочна, как и идея о том, что мозг состоит из клеток. С философской и психологической точек зрения мозг — это единое целое. Целое, согласно определению, определяется частями и их отношениями. Мы не можем описать мозг и проанализировать его, не зная его частей. Сложные целые (в том числе и мозг) представляют собой иерархию частей. Мы не уверены, что понимаем иерархию частей мозга, но мы на 100% уверены, что нейроны не являются первым уровнем иерархии мозга, то есть что мозг состоит из нейронов. Поэтому начинать строить модели работы мозга на основе перцептрона было плохой идеей.
- Другой основной идеей в русле ИИ было убеждение, что нейронной сети не нужны начальные знания — все, что потребуется, будет извлечено в процессе обучения. Это не так, потому что мы должны быть уверены, что входные данные, описание анализируемых объектов, должны содержать адекватную информацию. Например, нефтеразведка десятилетиями основывалась на органической теории происхождения нефти, и результаты были близки к случайным (или даже хуже). Использование ИИ было безуспешным, потому что теория была неверной. После того как была принята неорганическая теория происхождения нефти, а соответственно, изменились объект исследования и его описание, использование тех же инструментов ИИ резко улучшило показатели успешности нефтеразведки.
- Нейронные сети получают в наследие недостатки связанные с выбором перцептрона в качестве своей основы, представляя в виде растровых изображений цифры для различных видов обработки. Это согласуется с общепринятыми нейропсихологическими знаниями середины XX века об обработке изображений в нашем мозге. Позже было установлено, что мы не храним в памяти образы, а значит, не можем их наложить друг на друга и обобщить. Этот выбор дает единственную возможность не распознавать буквы, а имитировать распознавание букв и цифр, сохраняя в памяти все возможные варианты изображений цифр и букв. Именно это мы и наблюдаем на протяжении более чем 60-летней истории распознавания с помощью нейронных сетей: количество примеров, хранящихся в обучающих данных на одну букву, растет от десятков до тысяч.
- Параллельно с увеличением размера обучающего набора данных размерность векторного пространства росла с десятков до многих миллионов. Для чего это было сделано? Одна из главных целей любого усовершенствования — уменьшение количества ошибок в обучающем наборе данных после обучения. Нейронные сети делают это, создавая в многомерном пространстве поверхность, разделяющую точки, принадлежащие разным классам. В математике известно, что для любых двух наборов точек можно найти разделяющую функцию, если число измерений будет достаточно большим. С увеличением размерности разделяющей поверхности она становится все более сложной, разделяя пространство на все большее количество маленьких областей. Разделительная поверхность стала очень вариативной. Она позволяет правильно распознавать одиночные цифры одного класса, находящиеся внутри скопления точек, принадлежащих другому классу. В то же время возможно, что совсем рядом с точкой одного класса находится область, отмеченная функцией разделения как принадлежащая другому классу. Мы не узнаем об этом, пока на входе не появится изображение, представленное точкой, расположенной в этой области. Именно таким образом были обнаружены adversarial images..
- Для работы с большими массивами данных требуется больше вычислительной мощности, и это иногда становится ведущим требованием для усовершенствования нейронных сетей: "Все, что нам нужно для достижения этого лучшего на данный момент результата, — это много скрытых слоев, много нейронов на слой, множество деформированных обучающих изображений и графические карты для значительного ускорения обучения" (Ciresan et al. 2010). Это поставило точку в дискуссии об интеллекте нейронных сетей в тот момент (около 2012 года)
Современная тенденция
Более 10 лет назад произошел новый взрыв интереса к нейронным сетям и их использованию во многих областях. На основе современных нейросетей были созданы большие языковые модели (Large Language Models, LLM) для обработки текстов. Современное состояние предыдущего поколения нейронных сетей для распознавания образов на тот момент можно описать следующим образом:
- Производительность (коэффициент ошибок) различных распознавателей (нейронных сетей различной архитектуры, Support Vector Machine (SVM) и алгоритм "K-nearest") практически одинакова — менее 1%.
- Двумя двигателями, которые постоянно двигали вперед производительность нейронных сетей в течение 60 лет, были размер обучающего набора данных и перевод входных данных в более высокую размерность.
Можно ожидать, что работа больших языковых моделей с совершенно новым материалом и новыми целями потребует новых инструментов. Чтобы проверить это предположение, автор решил найти ответ в Google и сделал это с помощью ChatGPT-3.5, полагая, что Chat не будет свидетельствовать против себя. (Автор сделал это, основываясь на собственном опыте: последние месяцы автор успешно использовал ChatGPT-3.5 для сбора информации из Интернета). ChatGPT-3.5 был задан вопрос: "Какие существуют средства для улучшения моделей ChatGPT?". Ответ содержит список средств, и на первом и втором местах оказались "увеличение размерности пространства поиска" и "увеличение размера обучающего множества" — те самые средства, которые руководили развитием нейронных сетей предыдущие 20 лет.
Вот планы относительно будущего развития: "Уточняя обучающие данные, поощряя итеративную обратную связь и внедряя надежные механизмы проверки фактов, мы можем гарантировать, что модели ИИ, подобные ChatGPT, будут продолжать развиваться" (De Simoni 2023). Проясним упомянутые условия прогресса: первое — "улучшение обучающих данных", второе — "улучшение градиентного спуска". Оба продолжают основную линию развития, проводимую с самого начала истории нейронных сетей. Третье условие — "проверка фактов", которая является постпроцессингом и не влияет на производительность самой ЯП. Таким образом, перечисленные выше особенности, унаследованные нейронными сетями для распознавания изображений, остаются неизменными и при использовании нейронных сетей для обработки текстов. Тогда логично предположить, что болезни ChatGPT будут такими же, как и у предыдущих нейронных сетей. Повторим недостатки, обнаруженные в предыдущих нейронных сетях. Недостатков два: отсутствие обобщения и состязательные объекты. Прежде всего, давайте обсудим определения терминов. Наиболее общим понятием, которое мы обсуждаем, является интеллект. Все авторы, рассуждающие о нем, перечисляют несколько необходимых, но не достаточных неотъемлемых характеристик этого понятия. Без определения интеллекта невозможно доказать, что нейронные сети являются интеллектуальными. Но наша цель — доказать, что нейронные сети не обладают понятием интеллекта, поэтому будет достаточно доказать, что нейронные сети не обладают только одним из необходимых признаков (например, обобщением или пониманием). Согласно "Словарю психологии": "Обобщение — это процесс выведения концепции, суждения, принципа или теории из ограниченного числа конкретных случаев и применения ее в более широком смысле, часто к целому классу объектов, событий или людей" (https://dictionary.apa.org/generalization). Это значит, что ChatGPT, преследующий цель использовать для обучения неограниченное количество случаев, не обладал и никогда не будет обладать способностью к обобщению, а значит, никогда не будет обладать интеллектом. Поскольку тексты обладают таким неотъемлемым свойством, как смысл, это еще одно необходимое условие для интеллекта. Слово интеллект не поддается краткому описанию. Давайте заглянем в генеалогию этого слова: Слово интеллект происходит от латинских существительных intelligentia или intellectus, которые в свою очередь происходят от глагола intelligere — постигать. Comprehend часто немного сильнее, чем understand. Смысл — способность понимать. Это значит, что утверждать, что "текст, созданный разумным агентом, не может быть бессмысленным", будет вполне разумно. Вот пример.Вопрос к ChatGPT-3.5 был следующим:
Каков будет результат столкновения стула и религии? Первый ответ ChatGPT-3.5 был следующим:При метафорическом толковании столкновение стула и религии может символизировать столкновение между светскими и религиозными убеждениями или ценностями. Это столкновение может проявляться как конфликт между различными мировоззрениями, верованиями или практиками. На буквальном уровне столкновение стула и религии, скорее всего, приведет к физическому повреждению стула и потенциально символическим или метафорическим последствиям, связанным с конкретным религиозным контекстом. Например, в ходе религиозной церемонии или ритуала столкновение может быть истолковано символически в контексте верований и практик данной религии. В любом случае результат будет крайне субъективным и зависящим от индивидуальных взглядов, убеждений и интерпретаций.
Очевидно, что вопрос не имеет смысла, но Chat не распознал его, что невозможно для разумного агента. Все пять предложений ответа были сгенерированы чатом, и каждое из них не имеет смысла. Это говорит о том, что чат не может отличить осмысленные высказывания от бессмысленных ни в чужом, ни в своем тексте.Когда тот же вопрос был задан во второй раз, ответ был следующим:
Если мы рассматриваем буквальное столкновение между физическим стулом и концепцией религии, то результатом, скорее всего, будет повреждение стула и потенциально символические или метафорические интерпретации в зависимости от контекста. Например: Стул может сломаться или повредиться, в зависимости от силы столкновения. Символически столкновение может представлять собой столкновение светской и религиозной идеологий или влияние секуляризма на религиозные институты. В метафорическом смысле столкновение может означать вызов традиционным религиозным верованиям или практикам, а также сомнение в религиозном авторитете. Однако важно отметить, что этот сценарий является чисто гипотетическим и символическим. В реальности концепция религии не может физически столкнуться со стулом.
Второй текст имеет не больше смысла, чем первый, за исключением последней строки: "В действительности понятие религии не может физически столкнуться со стулом". Это был бы 100-процентный интеллектуальный ответ на поставленный вопрос. Это дополняет наше представление о степени интеллекта нейронных сетей: они не только не могут распознать бессмысленные высказывания, но и не могут распознать осмысленные. Стоит отметить, что найденное нейронной сетью правильное утверждение состоит из двух блоков, существующих в текстах в Интернете: "в реальности понятие религии" и "не может физически столкнуться с". Это характерно для больших языковых моделей. Таким образом, можно сделать вывод, что большие языковые модели не могут обобщать. Второй недостаток, присущий нейронным сетям для распознавания образов, — существование неблагоприятных образов (см. выше), которые можно назвать "обманными". Поскольку в больших языковых моделях обработка данных происходит так же, как и в нейронных сетях для распознавания образов, мы предполагаем, что в больших языковых моделях будет тот же недостаток. Пользователи, использующие и исследующие большие языковые модели, обнаружили явление, названное "галлюцинацией", которое означает ответ, сгенерированный нейронной сетью, содержащий ложную или вводящую в заблуждение информацию. Например (из Википедии), галлюцинирующий чатбот может, когда его просят сгенерировать финансовый отчет компании, ложно заявить, что доход компании составил 13,6 миллиарда долларов (или какое-то другое число, очевидно "взятое из воздуха"). Сегодня общепринятое мнение таково: "Несмотря на то, что исследовательское сообщество приложило немало усилий для разработки эмпирических методов измерения и смягчения галлюцинаций, наше понимание галлюцинаций больших языковых моделей остается ограниченным." В то же время в подробном обзоре эффективности больших языковых моделей (Ziwei 2024) утверждается, что "поскольку большие языковые модели генерируют очень беглые и убедительные ответы, их галлюцинации становится труднее идентифицировать, и они с большей вероятностью могут иметь вредные последствия". Наш анализ показывает, что причиной этого опасного явления является цепь неверных решений, принятых в самом начале. Во-первых, неудачный выбор входных параметров и меры близости. Она определяет плохую компактность классов (т.е. многие точки одного класса расположены между точками, принадлежащими другому классу). Чтобы уменьшить количество ошибок распознавания, было решено увеличить размерность пространства (ведь для любых двух наборов точек существует пространство такой большой размерности, в котором эти два набора могут быть разделены). Но за это пришлось заплатить большую цену: разделительная поверхность, разделяющая классы, стала насыщенной высокими частотами, область вокруг каждой точки в обучающем множестве стала очень маленькой, и появилась возможность того, что рядом с точкой одного класса появится область, принадлежащая другому классу. Учитывая, что когда чат-бот выдает ложное или вводящее в заблуждение сообщение (галлюцинацию), пользователь оказывается одураченным ("adversarial attack"), можно сделать вывод, что оба поколения нейронных сетей страдают от одного и того же недостатка. Сообщество разработчиков и пользователей нейронных сетей отказалось от использования термина adversarial и заменило его более очеловеченным термином hallucination, чтобы подчеркнуть сходство нейронных сетей с человеческим мозгом.Заключение
Ни нейронные сети для распознавания образов, ни большие языковые модели не обладают достаточной функциональностью, чтобы считаться интеллектуальными.
Благодарности
Эта статья никогда не была бы написана, если бы не многочисленные беседы, которые я веду на эти темы с Александром Пашинцевым вот уже 30 лет.